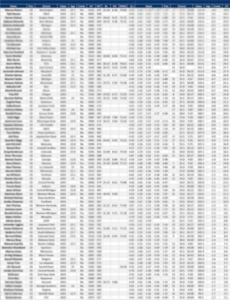
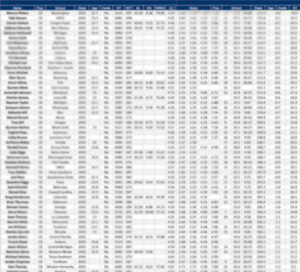
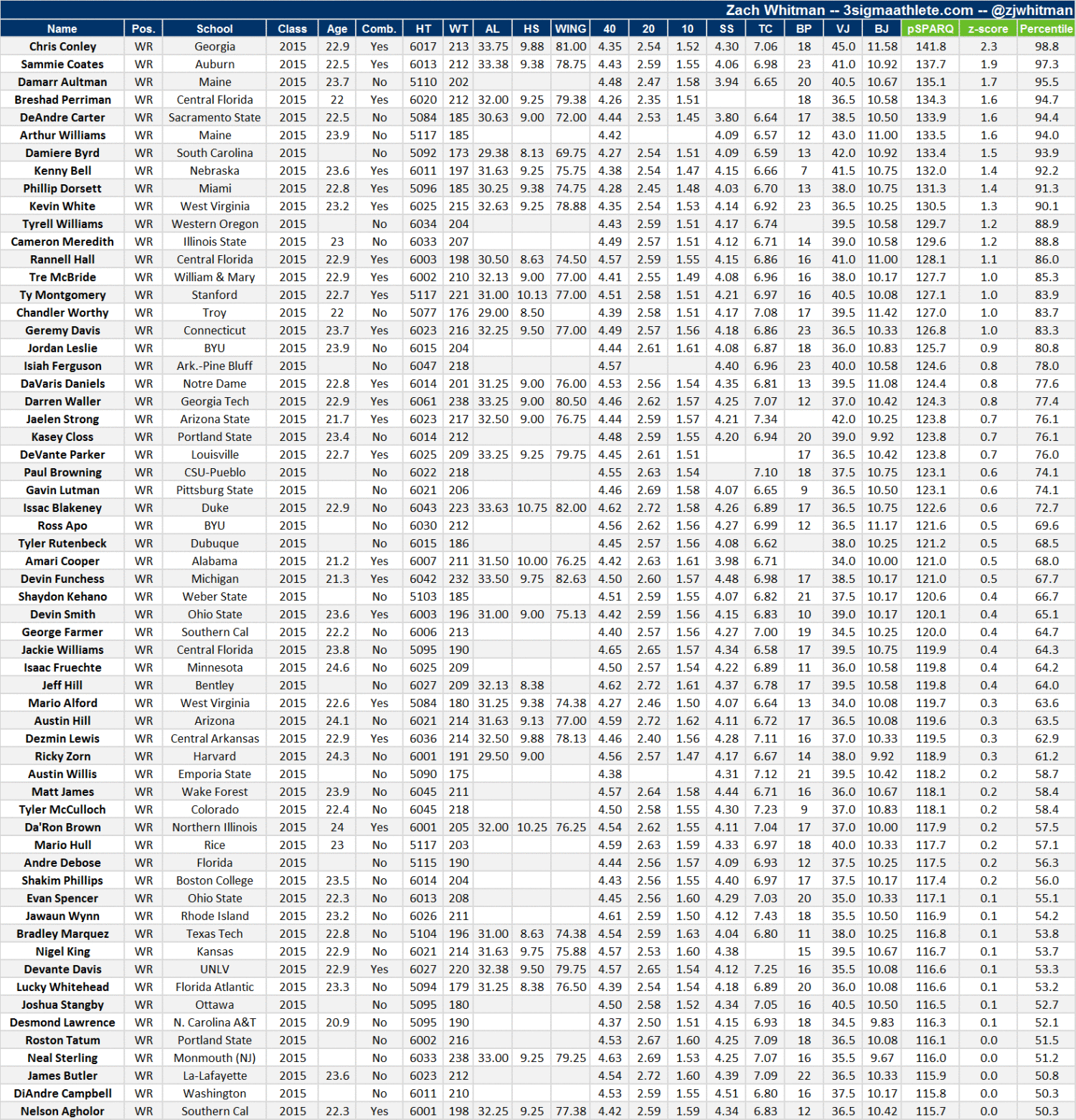
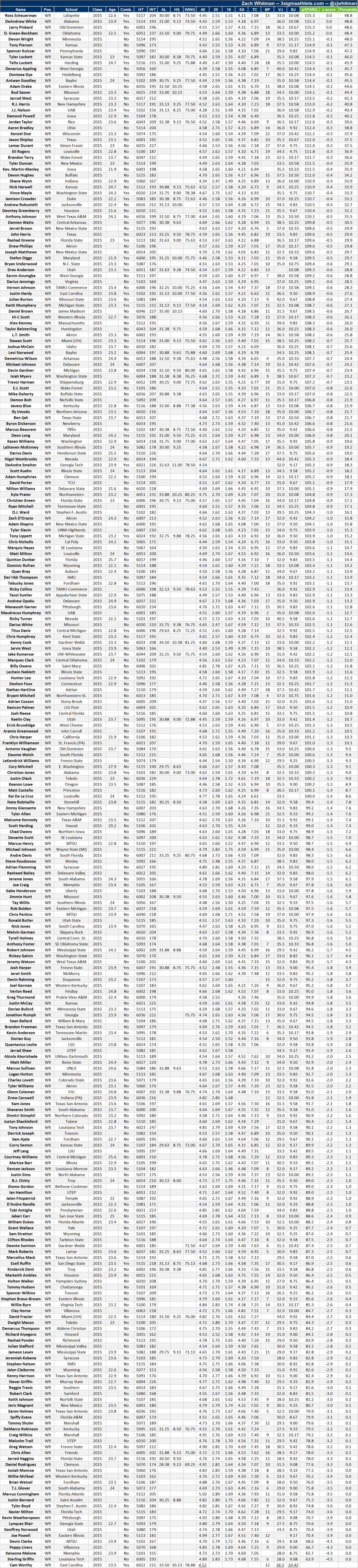
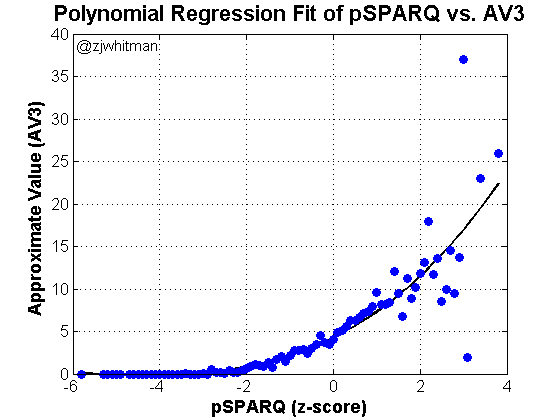
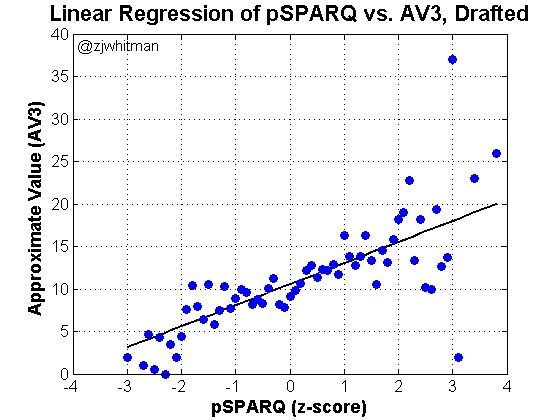
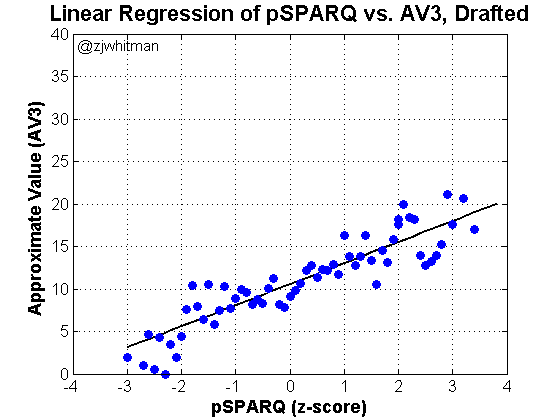
Draft analytics aren’t necessarily about athleticism or SPARQ; the idea is to use data in a way that maximizes the use of draft capital. Before we discuss the specific model used here, it’s important to lay out the tools we’ll use in the analysis.
Approximate Value – Approximate Value is used to empirically measure player production. It’s not a perfect stat and won’t perfectly capture behavior at each position, but it functions well given a “large-enough” data set. As before, I’ll specifically use AV3, the sum of a given player’s best 3 seasons by Approximate Value. For a more detailed description of the stat, I’ll refer you to an earlier piece I wrote on the subject.
Bounds – This model includes all players drafted from 1999-2012. The information from 2013 and 2014 is potentially useful, but will not be utilized here as I hesitate to judge a player without 3 seasons of performance. Including the most recent draft classes would also mean comparing the career starts of the 2013/2014 prospects vs. the career peaks of players drafted in the mid-2000s and before.
ExpectedAV3 – Using the 99-12 player set, it’s possible to develop the average AV3 of players drafted in each round by position. This means we know what kind of AV3 is produced by a 5th-round running back, 3rd-round corner, and so on. To ensure as little bias as possible, ExpectedAV3 has been normalized by position.
Hit Rate – I’ve arbitrarily defined a “hit” as a player who generates an AV in the top 30% of all drafted players from the same position group. This gives us a metric which lends a bit more context than simply looking at raw Approximate Value stats. Note that I’ve used AV1, AV3, and AV5 in determination of hit rate. This means that a player can qualify with one exceptional year, three very good years, or five good-but-less-than-great years.
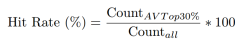
The 30% requirement for Hit Rate is arbitrary, but it serves us well for this purpose. The trends for each position from round-to-round are what we care about, and they’re fairly stable regardless of the benchmark value used to define a hit. 30% is also convenient as most successful NFL players fall in the top 30% of draftees at their position.
Positional ExpectedAV3 Curves
The most logical first step is to simply examine how a position varies with ExpectedAV3 by round. Note that the statistic is normalized such that an ExpectedAV3 equal to 1 is equivalent to the average player drafted at the position. This means that a player with ExpectedAV3 = 2 has produced double the average AV for the given position.
The following plot shows a typical ExpectedAV3 curve. Note that I’ve split up Round 1 into two sections – picks 1-16 are located at “1” on the x-axis and picks 17-32 are located at “1.5.”
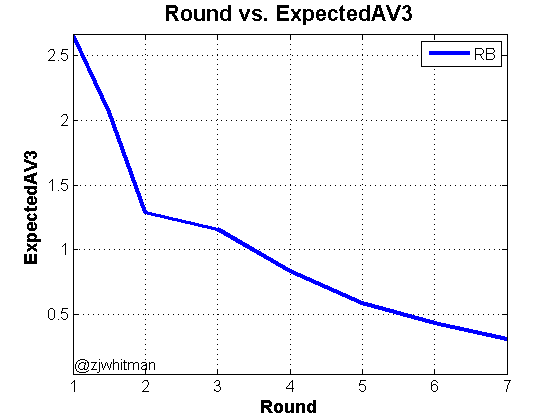
The most interesting part of the ExpectedAV3 plots is where the plateaus and drop-offs occur. With the above plot, we can see that there isn’t a huge difference between a running back drafted in the 2nd and 3rd round, but that group is much less productive than 1st-rounders and much more productive than 4th-rounders.
It’s still difficult to parse what exactly it means without relating it to other positions. Sure, we see a steep drop-off in production after the early rounds, but that’s not new information. It’s necessary to add context, and just stacking each position group in the same plot makes it too messy to discern much of anything.
MarginalAV3 Plots
To generate a plot that’s more visually digestible, I’ll use MarginalAV3, calculated by the following formula.
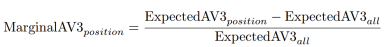
MarginalAV3 relates the average positional production for each round with the overall average. In simple terms, positions which produce more than expected in a particular round will have a positive value of MarginalAV3, and positions which are inefficient will have a negative MarginalAV3.
The following bar plots show the efficiency of each position group at each round.
Marginal Offensive Plots
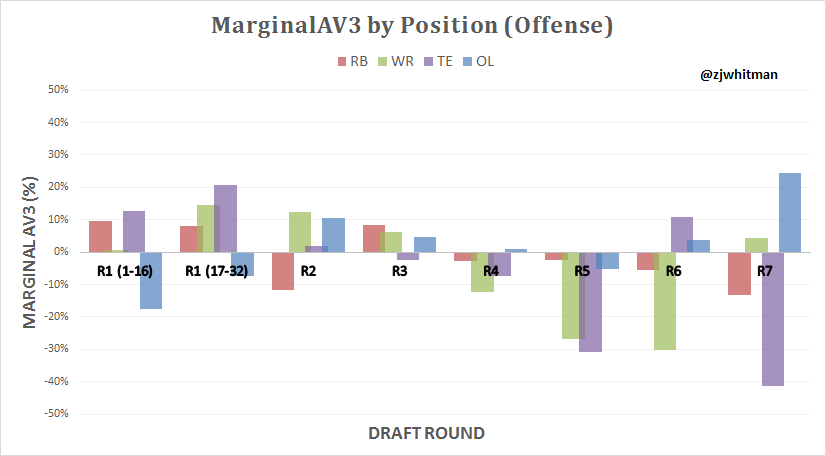
I would note that the sample size for tight ends is lower than that of other positions, so I’d take the large swings of rounds 5-7 with a grain of salt. The general trend is that the early rounds are where most relative tight end value is obtained, and there aren’t many tight ends drafted after the fourth round who yield much value.
There’s a clear trend overall that offensive picks struggle from the 4th-6th rounds. The second round produces the most positive offensive value on average.
It’s apparent that wide receivers are a particularly terrible value pick in the 4th-6th rounds, but tend to produce surplus value in the 2nd, 3rd, and 7th rounds. In Ted Thompson’s time as the general manager in Green Bay, he’s drafted 14 receivers. 10 of the 14 have come in surplus rounds, with only four being selected in the negative value rounds. Note that only one of the receivers from the negative value group was drafted after Thompson’s first three years as Green Bay GM.
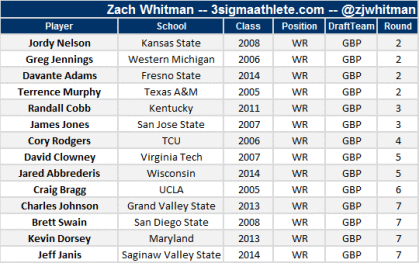
In Bill Belichick’s 15 New England drafts, he’s selected 10 of his 13 receivers in positive MarginalAV3 rounds, as shown below. While New England isn’t regarded as a wide receiver factory like Green Bay, they are more analytically-focused than most NFL franchises. It’s thus interesting to see how their draft strategy does or doesn’t conform to the data presented here.
The splits for the Patriots and Packers aren’t due to a league-wide shortage of receivers drafted in the negative value region. The 4th-6th average about the same number of WR picks as observed in the 2nd and 3rd rounds.
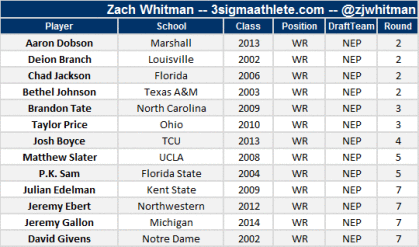
Marginal Defensive Plots
This plot is a bit more striking. We see that the biggest misses in early rounds are on EDGE players (and DL to a lesser extent). This isn’t saying that the great pass rushers aren’t found in the first round; the point is that teams aren’t good at evaluating EDGE players. DL and EDGE are less efficient markets than RB and WR; teams miss early more on the DL/EDGE than they do at any other position.
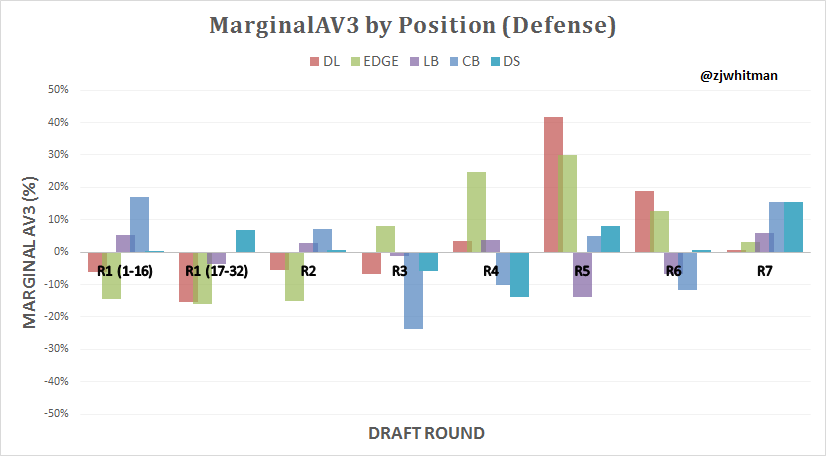
Hit Rate Plots
It’s important to understand context here. It’s not a perfect strategy to only select defensive linemen in the 5th round; though this may historically be the most efficient round for the position, there still isn’t a great shot of getting a significant contributor. The hit rate at all positions in late rounds is low, and this data should be used in conjunction with the marginal plots.
The following plots show the hit rate of players drafted at each position in each round. As noted earlier, hit rate refers to all players who produced in the top 30% of their position according to AV criteria.
On Offense

Star tight ends are frequently drafted early. It typically requires a very high grade for a tight end to be among the first 32 selections, and the hit rate ends up being the highest among all positions. Now, this sample is relatively small, and the 2013 and 2014 TE classes may end up bringing this total down closer to the mean.
It’s still apparent that the hit rate on tight ends diminishes significantly after the 4th round. Now, this analysis does not distinguish between blocking and move tight ends, and that may be an important caveat to consider. My contention is that that prolific receiving tight ends are gone by the 4th and that it’s more difficult to make an assessment of blocking tight end value in the last three rounds of the draft.
Also: beware the second round running back. I’d let another team take the first RBs off the second tier and wait for whoever falls.
After the first 40 or so selections of the draft’s third day, the offensive skill position players are just about equivalent to priority undrafted free agents.
On Defense
The most striking thing about this plot, as with marginalAV3, is the hit rate on Edge players in the middle of the draft. The hit rate only decreases 9% from Round 2 to Round 5, with an uptick in Round 3. The implication is not that Round 3 Edge players are better than their second round counterparts. It’s that the evaluation process is so scattershot that there isn’t much of a difference in outcomes. The second tier of the draft was not correctly identified by NFL scouts over the 14-year sample.
A potential issue at play here is over-drafting. There were 116 first-round EDGE and DL players drafted in our data set. When contrasted with the 68 OL drafted in the first over that span, it’s easy to see that there’s a premium being placed on the defensive front. The upper tier is already gone by the second round, leaving teams with plenty of room to whiff on their favorite second-tier prospect.
What We Do Now
The optimal strategy isn’t simply to draft the highest value player in each round. Teams need players at every position, not just the one that produces optimal value. So, how do we use this data to inform the draft process? Let’s take a look at a classic case.
As Eric Stoner noted last week, Anthony Chickillo is an interesting prospect, but the general thought is that he’ll go during Day 3 of the draft, right in the 4th/5th round sweet spot shown earlier in the MarginalAV3 plots. The problem with Chickillo is that he was used at Miami in a role very different to the one he’ll play in the NFL, and my feeling is that this phenomenon is the reason for the much of the uncertainty in DL/EDGE evaluations in general.
College teams just often don’t use EDGE and DL players correctly, and even if they’re utilized well, it’s often in roles that won’t be replicated at the next level. This means tape study leans more and more to the projection side of the spectrum and becomes less accurate. The knowledge of this should probably change the way we interpret these prospects and their evaluations.
While the data says that there’s less value at some positions in some rounds, it doesn’t imply that there’s never value there. Antonio Brown was drafted in the 6th round, defying the odds. Most superstar pass rushers are selected in the first round, even if the bust frequency is a little high relative to other positions.
Still, EDGE players are over-drafted, most pass-catchers are typically gone by the 4th round, and the third round of cornerbacks are one of the worst value propositions around. This knowledge is valuable and should be incorporated into the analysis.
My recommended draft strategy would tend toward drafting offensive players in the 2nd and 3rd rounds while peppering the 4th-6th with volume picks on the defensive side of the ball. Though I don’t support strictly ruling out certain positions/round combinations, there would have to be compelling evidence toward a given prospect for me to feel comfortable drafting from a severely negative area, like 2nd-round pass rushers, 3rd-round corners, or 6th-round receivers. Perhaps most importantly, I would utilize the plateaus, like 2nd-5th round EDGE and 2nd-3rd round RB, to acquire prospects with similar hit rates to peers that were drafted earlier.
The data doesn’t necessarily make us better at drafting, but it should certainly make us more cognizant of where we’ve failed in the past. Being aware of these systemic trends is the first step toward eliminating them.
–ZW